mkdir
The mkdir command can create a new folder, e.g. mkdir temp would create the directory temp in the present working directory.
Example command output as below:
debix@imx8mpevk:~$ mkdir temp
debix@imx8mpevk:~$ ls
Desktop Documents Linux Pictures Templates gstshark_2022-04-21_12:54:49
Device Downloads Music Public Videos temp
cd
The cd command can change the current directory to the one specified. You can use relative (i.e. cd temp) or absolute (i.e. cd /home/debix/temp) paths.
Example command output is as below:
debix@imx8mpevk:~$ cd temp/
debix@imx8mpevk:~/temp$
ls
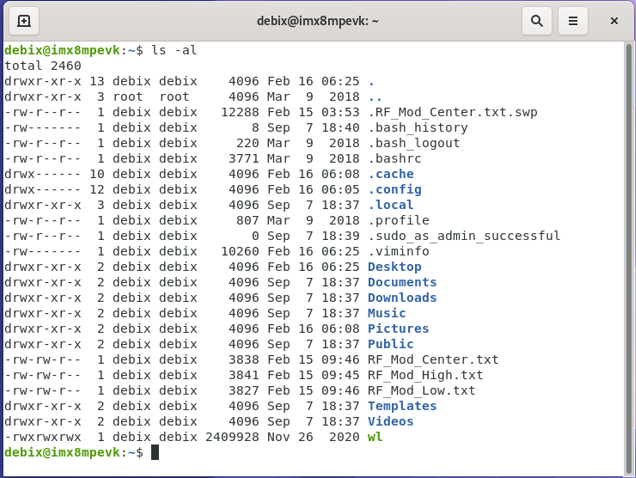
The ls command lists the content of the current directory (or one that is specified). It can be used with the -l flag to display additional information (permissions, owner, group, size, date and timestamp of last edit) about each file and directory in a list format. The -a flag allows you to view files beginning with . (i.e. dotfiles).
Example command output is as below:
debix@imx8mpevk:~$ ls
Desktop Documents Linux Pictures Templates gstshark_2022-04-21_12:54:49
Device Downloads Music Public Videos temp
rm
The rm command removes the specified file (or recursively from a directory when used with -r).
Cautions
Be careful with this command: files deleted in this way are mostly gone.
|
Example command output is as below:
debix@imx8mpevk:~/temp$ rm -f temp.txt
debix@imx8mpevk:~/temp$ cd ..
debix@imx8mpevk:~$ rm -rf temp
debix@imx8mpevk:~$ ls
Desktop Device Documents Downloads Linux Music Pictures Public Templates Videos gstshark_2022-04-21_12:54:49
pwd
The pwd command displays the name of the present working directory: on a DEBIX, entering pwd will output something like /home/debix.
Example command output is as below:
debix@imx8mpevk:~$ pwd
/home/debix
rmdir
The rmdir command removes empty directories.
Example command output is as below, directory tmp_dir1 is empty, it can be removed by rmdir, directory tmp_dir2 is not empty, it cannot be removed by rmdir:
debix@imx8mpevk:~/mytemp$ ls
debix.txt main.py tmp_dir1 tmp_dir2
debix@imx8mpevk:~/mytemp$ ls tmp_dir1
tmp_file1
debix@imx8mpevk:~/mytemp$ ls tmp_dir2
debix@imx8mpevk:~/mytemp$ rmdir tmp_dir1
rmdir: failed to remove 'tmp_dir1': Directory not empty
debix@imx8mpevk:~/mytemp$ rmdir tmp_dir2
debix@imx8mpevk:~/mytemp$ ls
debix.txt main.py tmp_dir1
debix@imx8mpevk:~/mytemp$
cp
The cp command makes a copy of a file and places it at the specified location (this is similar to copying and pasting). For example, cp ~/file1 /home/otheruser/ would copy the file file1 from your home directory to that of the user otheruser (assuming you have permission to copy it there). This command can be used as below:
-
cp FILE FILE (cp file1 file2), copy file1 to file2.
-
cp FILE DIR (cp file1 /temp/) ,it copies file1 to the directory /temp/.
-
cp -r DIR DIR (cp -r dir1 dir2), it recursively copies contents of dir1 to dir2.
Example command output as below:
debix@imx8mpevk:~$ ls
Desktop Device Documents Downloads Linux Music Pictures Public Templates Videos file1 gstshark_2022-04-21_12:54:49
debix@imx8mpevk:~$ sudo cp ~/file1 /home/otheruser/
debix@imx8mpevk:~$ cd /home/otheruser/
debix@imx8mpevk:/home/otheruser$ ls
file1
mv
The mv command moves a file and places it at the specified location (so where cp performs a 'copy-paste', mv performs a 'cut-paste'). The usage is similar to cp. So mv ~/file1 /home/otheruser/ would move the file file1 from your home directory to that of the user otheruser(assuming you have the permission). This command can be used as below:
-
mv FILE FILE (mv file1 file2), move file1 to file2.
-
mv FILE DIR (mv file1 temp_dir1/), move file1 from the current location to directory temp_dir1/.
-
mv DIR DIR (mv temp_dir1/ temp_dir2/), move directory temp_dir1 to directory temp_dir2.
Example command output is as below:
debix@imx8mpevk:~$ ls ~
Desktop Downloads Pictures Templates file1
Documents Music Public Videos gstshark_2022-07-13_09:11:19
debix@imx8mpevk:~$ sudo mv file1 /home/otheruser/
debix@imx8mpevk:~$ ls
Desktop Downloads Pictures Templates gstshark_2022-07-13_09:11:19
Documents Music Public Videos
debix@imx8mpevk:~$ ls /home/otheruser
file1
debix@imx8mpevk:~$
cat
The cat command lists the contents of file(s), e.g. cat file1 will display the contents of file1. This command can also be used to list the contents of multiple files, i.e. cat *.txt will list the contents of all .txt files in the current directory.
Example command output is as below:
debix@imx8mpevk:~$ ls
Desktop Device Documents Downloads Linux Music Pictures Public Templates Videos file1 gstshark_2022-04-21_12:54:49
debix@imx8mpevk:~$ cat file1
This is a test!
head
The head command displays the beginning of a file. Can be used with -n to specify the number of lines to show (by default ten), or with -c to specify the number of bytes.
Example command output is as below:
debix@imx8mpevk:~$ head -n 1 file1
This is a test!
chmod
The chmod command can change the permissions for a file. The chmod command can use symbols u (user that owns the file), g (the files group), and o (other users) and the permissions r (read), w (write), and x (execute). Using chmod u+x filename will add execute permission for the owner of the file.
Example command output is as below:
debix@imx8mpevk:~$ ls -l test.sh
-rw-rw-r-- 1 debix debix 32 Jul 22 02:35 test.sh
debix@imx8mpevk:~$ chmod +x test.sh
debix@imx8mpevk:~$ ls -l test.sh
-rwxrwxr-x 1 debix debix 32 Jul 22 02:35 test.sh
debix@imx8mpevk:~$
ssh
ssh connects to another computer using an encrypted network connection. For more information, you can check SSH (secure shell)
Example command output is as below:
debix@imx8mpevk:~$ sudo ssh debix@192.168.1.10
ECDSA key fingerprint is SHA256:4wru1tGenheRduefLj00n6J+dqLJORbylnmWsAwxVmc.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added '192.168.1.10' (ECDSA) to the list of known hosts.
debix@192.168.1.10's password:
Welcome to Ubuntu 20.04.4 LTS (GNU/Linux 5.10.72-lts-5.10.y+g3f536c684411 aarch64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
This system has been minimized by removing packages and content that are
not required on a system that users do not log into.
To restore this content, you can run the 'unminimize' command.
Last login: Wed Jul 20 08:50:43 2022 from 192.168.1.8
debix@imx8mpevk:~$
scp
The scp command copies a file from one computer to another using ssh. For more details see SCP (secure copy)
Example command output is as below:
debix@imx8mpevk:~/Documents$sudo scp debix@192.168.1.10: ~/file1 /home/debix/Documents/
[sudo] password for debix:
debix@192.168.1.10's password:
file1
100% 16 33.1KB/s 00:00
debix@imx8mpevk:~/Documents$ ls
file1
dd
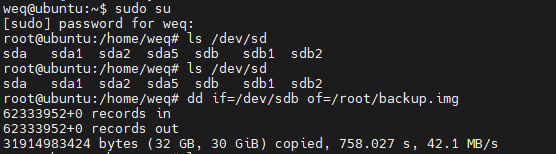
The dd command copies a file converting the file as specified. It is often used to copy an entire disk to a single file or back again. So, for example, dd if=/dev/sdd of=backup.img will create a backup image from an SD card or USB disk drive at /dev/sdd. Make sure to use the correct drive when copying an image to the SD card as it can overwrite the entire disk.
df
The df command can display the disk space available and used on the mounted filesystems. Use df -h to see the output in a human-readable format using M for MBs rather than showing number of bytes.
Example command output is as below:
debix@imx8mpevk:~$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/root 29G 5.6G 22G 21% /
devtmpfs 494M 0 494M 0% /dev
tmpfs 975M 0 975M 0% /dev/shm
tmpfs 195M 3.4M 192M 2% /run
tmpfs 5.0M 4.0K 5.0M 1% /run/lock
tmpfs 975M 0 975M 0% /sys/fs/cgroup
tmpfs 195M 1.3M 194M 1% /run/user/1000
tmpfs 195M 36K 195M 1% /run/user/114
tar
The tar command stores or extracts files from a tape archive file. It can also reduce the space required by compressing the file similar to a zip file.
Example command output is as below:
debix@imx8mpevk:~$ tar -cvf test.tar test.sh
test.sh
debix@imx8mpevk:~$ ls
Desktop Device Documents Downloads Linux Music Pictures Public Templates Videos backup.img file1 gstshark_2022-04-21_12:54:49 test.sh test.tar
When creating a compressed file, use command tar -cvzf filename.tar.gz directory/. To extract the contents of a file, use command tar -xvzf filename.tar.gz
unzip
The unzip command extracts the files from a compressed zip file.
pipes
The pipe symbol is a vertical line |. A pipe allows the output from one command to be used as the input for another command. For example, run command cat tmp.txt | grep "hello", the output of command cat tmp.txt will be provided as input for command grep -o "hello". Example command output is as below:
debix@imx8mpevk:~$ ls
Desktop Downloads Pictures Templates gstshark_2022-07-13_09:11:19
Documents Music Public Videos tmp.txt
debix@imx8mpevk:~$ cat tmp.txt
helloworld.
debix@imx8mpevk:~$ cat tmp.txt | grep -o "hello"
hello
debix@imx8mpevk:~$
&
Run a command in the background with &, freeing up the shell for future commands.
tree
Use the tree command to show a directory and all subdirectories and files indented as a tree structure. You can install it with APT:
sudo apt install tree
curl
Use curl to download or upload a file to/from a server. By default, it will output the file contents of the file to the screen. You can install it with apt:
sudo apt install curl
wget
Download a file from the web directly to the computer with wget.
wget https://www.debix.io/public/uploads/files/20220127/68e3735204a9f7e09114e2ee677a7c9e.pdf command will download the 68e3735204a9f7e09114e2ee677a7c9e.pdf datasheet and save it as 68e3735204a9f7e09114e2ee677a7c9e.pdf.
man
Show the manual page for a file with man. To find out more, run man man to view the manual page of the man command. Right now, on DEBIX, you need to run the following command to get manpages:
sudo unminimize









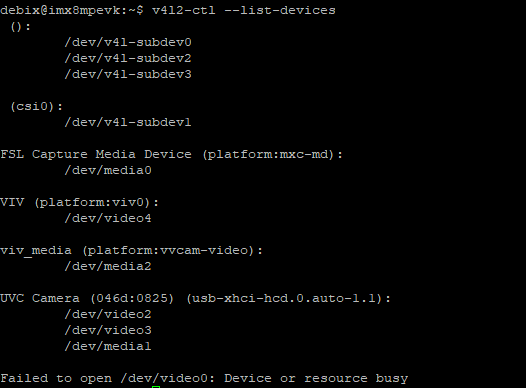


 to take a picture, and the photo is saved in the default path of “/home/Pictures”; at the same time, you can choose "Effects" to adjust the image window background. As shown in the figure below:
to take a picture, and the photo is saved in the default path of “/home/Pictures”; at the same time, you can choose "Effects" to adjust the image window background. As shown in the figure below: